
Mit Domain-Driven Design erzeugen Domänenexpert/inn/en und ein Entwicklungsteam gemeinsam ein Domänenmodell. Doch womit sollte man das erstellen und wo aufheben, so dass es immer stimmt? Ich plädiere für genau einen Platz: den Quellcode.
Letzte Woche: Aggregate Design
Mit der Event Storming Technik, die ich in meinen Domain-Driven Design Trainings unterrichte, kann man auf mehreren Ebenen arbeiten: System- oder Business-Überblick, dann auf der Prozessebene und letztlich auf der Software Design-Ebene.
In meinem Video vom letzten Freitag zeigte ich live, wie ein Aggregate Design entsteht. Es kam eine Vorstufe dieses kleinen Modells heraus, an dem ich heute noch etwas gefeilt habe:
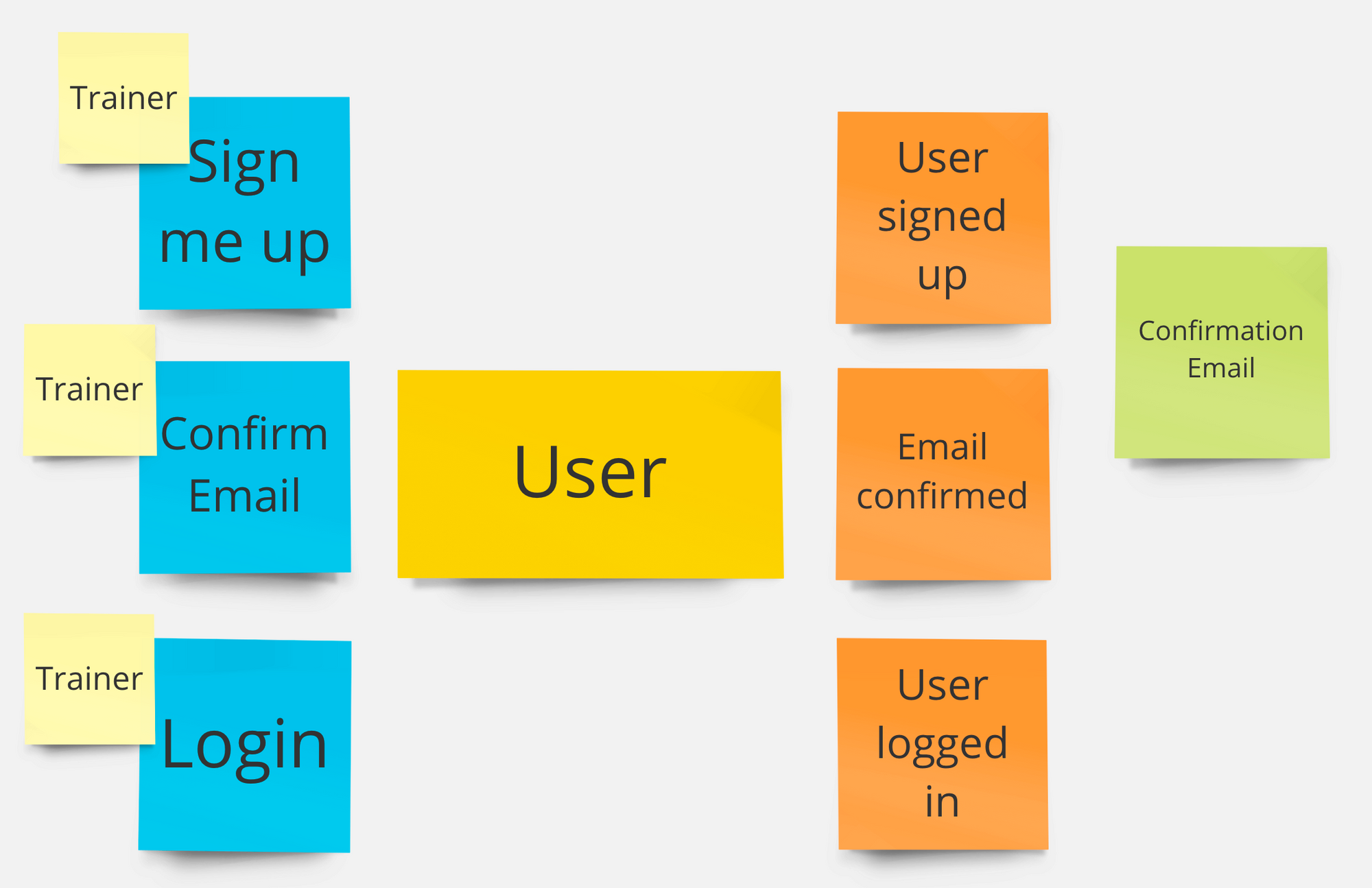
Diese Post-Its, die man an eine große Wand klebt (oder, falls online, auf einem Whiteboard wie Miro erstellt), zeigen eine gelbe "Stelle" im System, die User heißt (IT-Leute wissen, dass dies ein Aggregate ist). Dieses User-Aggregate kann drei Commands verarbeiten (Sign me up, Confirm email, und Login). User nimmt die Commands an, tut das Gewünschte und bestätigt dann, indem es Events verschickt: User signed up, Email confirmed, und User logged in. Draußen sitzt eine Person namens Trainer, welche diese Commands via UI an das System gibt.
Code und Modell laufen auseinander
Heute, in der sechsten Folge des Devlog, tat sich folgendes: Ich habe dieses Modell im Code abgebildet und funktionieren lassen. Man kann sich registrieren, einloggen, ausloggen und seinen Account löschen. Läuft.
Diese Woche fiel mir nun auf, dass der Code in gewisser Weise anders aussah als das Modell vom letzten Freitags-Video. Außerdem würde, wenn das so weitergeht, das Modell schnell veralten. (Die Post-Its stellen ja immer nur den Stand des Wissens dar, den die Menschen hatten, zu dem Zeitpunkt, als sie vor der Wand standen und die Post-Its klebten.)
Die Lösung: Reverse Engineering
OK, da musste also eine Lösung her, denn Teams, die Software bauen, sollten auch eine immer aktuelle Softwarearchitekturdokumentation haben, zu der ja auch das Domänenmodell gehört. Deshalb habe ich letzte Woche schon begonnen, das Domänenmodell aus dem Code automatisiert zurückzugewinnen.
Diese Woche klappte das dann. Hier als Beispiel das Stück Domänenmodell, das aus dem Code des Moduls user automatisch erzeugt wurde:
Noch vor ein paar Jahren hätte ich behauptet, das ginge nicht, denn man würde viel zu viele technische Details zu sehen bekommen, inklusive aller Hilfs- und Boilerplate-Klassen. Doch heute sind die Frameworks, die wir verwenden, und die Programmierkunst insgesamt auf einem Niveau angekommen, die Reverse Engineering nützlich machen. Fachleute bekommen dadurch nicht den gesamten Code auf dem Bild zu sehen, sondern nur das, was für das Verständnis des Systems wichtig ist.
Modell mit Post-Its vergleichen
Wenn Sie genau hinsehen, dann erkennen Sie sowohl Gemeinsamkeiten als auch Unterschiede zwischen den beiden Modellen (ja, auch Post-Its sind ein Modell):
- Zwei der blauen Zettel finden Sie im Code mit leicht anderen Namen wieder, den dritten (Confirm email) nicht, weil er nur aus einem Klick des Trainers auf einen Link besteht, den er in seiner E-Mail findet. Ganz ähnlich sieht es bei den orangen Events aus.
- Das gelbe Aggregate ist ebenfalls vorhanden, unterstützt durch zwei weitere Elemente: der UserAppService macht das Aggregate nach außen zugänglich, und das UserRepository macht User speicherbar und wiederauffindbar.
- Ein blaues Command namens Cancel account ist dazugekommen. Die GDPR (DSGVO) schreibt ja vor, dass User ein Recht auf Löschung ihrer Daten haben, also muss es als Gegenstück zu Signup auch ein Cancel account geben.
- Der grüne Zettel fehlt komplett. Da hat wohl jemand im Code nicht genau genug gearbeitet, so dass der Modellgenerator das grüne Element Read model nicht gefunden hat. Wer das wohl gewesen sein könnte?
- Auffallend ist der PersistentTokenBasedRememberMeService, der zum Zeitpunkt der Post-Its noch gar nicht geplant war. Er ist ein technischer Service, der zu jedem eingeloggten User eine zufällige Zahl liefert, die man in ein Cookie schreiben kann. Bei jedem Web-Request des Users wird das Cookie mit übertragen, so dass der Server weiß, für wen er arbeitet. Beim Logout oder bei Cancel account löscht der Server das Cookie wieder.
- Als zusätzliche Komponente fällt noch ImageRepository auf. Das ist eine Ablage (hier: AWS S3), auf der das System das Profilbild des Users ablegen kann, sofern dieser es hochlädt. Auch dies war noch nicht geplant, doch habe ich es hinzugefügt, weil alle SaaS, die ich kenne, dieses Feature haben.
Durch die Automatisierung des Reverse Engineerings bleibt das Domänenmodell stets aktuell. Es stimmt immer mit dem lauffähigen Code überein. Auch haben die Entwickler dadurch weniger Aufwand mit der Wartung, weil der Continuous Build-Server nicht nur die Software, sondern auch die Dokumentation immer frisch baut und veröffentlicht. Ich habe ein Gradle-Plugin geschrieben, denn mein Continuous Build läuft mit Gradle.
Das Modell mit den Fachleuten besprechen
Was machen wir mit solchen Bildern? Ich empfehle immer, dass Entwickler beim Review nicht nur das lauffähige neue Feature zeigen, sondern auch solche Stücke aus dem Domänenmodell, damit alle Vokabeln der Domänensprache (zum Beispiel Cancel account, das es vorher nicht gab) wirklich immer bei allen Beteiligten eines Bounded Context bekannt sind. Dadurch wird die Domänensprache wirklich allgegenwärtig, eine ubiquitous language.
Entwickler sollten das Modell auf dieser hohen Ebene erklären und Fragen beantworten können:
- Was macht jeder Baustein?
- Wie spielen sie zusammen, kann man vielleicht eine Geschichte dazu erzählen?
- Warum habt Ihr es anders gemacht, als wir vor zwei Wochen besprochen haben?
- Was habt Ihr gegenüber dem letzten gemeinsamen Stand geändert, den wir hatten?
- usw.
Fachleute sollten Feedback zum Modell geben, damit die Qualität und das gemeinsame Verständnis hoch bleiben. Sagen Sie den Entwicklern klar, was Sie verstehen und was nicht, und wo Sie Änderungsbedarf sehen. Sie als Fachmensch haben in Domain-Driven Design dieselbe Menge an Verantwortung für ein korrektes Modell wie die Entwickler, dafür eben auch entsprechende Gestaltungsmöglichkeiten!
Ausblick
Diese Domänenmodelle sollten auch Bestandteil der Architekturdokumentation sein, denn sie bestimmen ja die fachliche Architektur. Es fehlen noch zwei Ebenen darüber, nämlich die Kontextsicht und die Sicht auf die top-level Subsysteme des Systems. Diese stelle ich später zur Schau, sobald ich mehr Module im System SaaS für Trainer haben werden.
Möchten Sie auch stets aktuelle Modelle und Doku?
Dann üben Sie das mit mir! Am 27./28. Mai 2020 ist der nächste Termin für ein iSAQB® Advanced Level Training Softwarearchitektur dokumentieren (Details und Link zur Anmeldung hier). Ich zeige Ihnen, wie Sie Schritt für Schritt zu einer solchen größtenteils automatisierten und sehr pflegeleichten Dokumentation kommen, versprochen!
Geben Sie mir bitte per E-Mail Bescheid, wenn Sie auch einen Selbststudiums-Kurs für automatisierte Modell- und Doku-Erstellung haben möchten. Dann werde ich einen solchen Kurs erstellen.
Welche Konventionen und Strukturen Sie im Quellcode brauchen, um bis zu diesem Stand der Generierung zu kommen, beschreibe ich in einem separaten Artikel.
Titelfoto
Vielen Dank an den Fotografen Holger Link:






Kommentare