
Wer kennt es nicht: Ein neues Feature soll schnell umgesetzt werden, und sechs Monate später kämpft das Team mit einem undurchdringlichen Geflecht aus Abhängigkeiten, fragilen Tests und Code, den niemand mehr anfassen möchte. Die gute Nachricht: Es gibt einen besseren Weg. Gute Softwarearchitektur ist kein theoretisches Luxusgut, sondern ein konkretes Investment in die Zukunft eines Projekts – eines, das sich in kürzerer Zeit auszahlt, als die meisten denken.
KI-Assistenten fangen gerade erst an, das zu verstehen. Ich zeige Ihnen jetzt, was Sie Ihrem eigenen Assistenten beibringen müssen.
Lieber als Video anschauen? Hier starten!
Code, den alle lieben – Ist das überhaupt möglich?
Die Interessen scheinen auf den ersten Blick unvereinbar: Entwickler wünschen sich Code, der sich leicht verstehen und erweitern lässt. Benutzer erwarten eine zuverlässige, performante Anwendung ohne Bugs. Das Business will Features schnell und kostengünstig umsetzen können. Doch diese Ziele widersprechen sich nicht – sie alle wurzeln in derselben Grundlage: Qualität durch durchdachte Architektur.
Wenn wir von "gutem Code" sprechen, meinen wir Code, der morgen genauso verständlich ist wie heute. Code, bei dem eine Änderung nicht zum Ratespiel wird. Code, der testbar ist, ohne dass man eine Produktionsdatenbank hochfahren muss. Code, der robust auf unerwartete Situationen reagiert, statt schweigend falsche Daten zu produzieren.
Die Prinzipien, die wir gleich betrachten werden – hexagonale Architektur, "Parse, don't validate", und modularer Aufbau entlang von Bounded Contexts – sind keine abstrakten Konzepte. Sie sind bewährte Werkzeuge, die uns helfen, diese Qualitäten systematisch in unsere Software einzubauen.
Hexagonale Architektur – Das Herzstück schützen
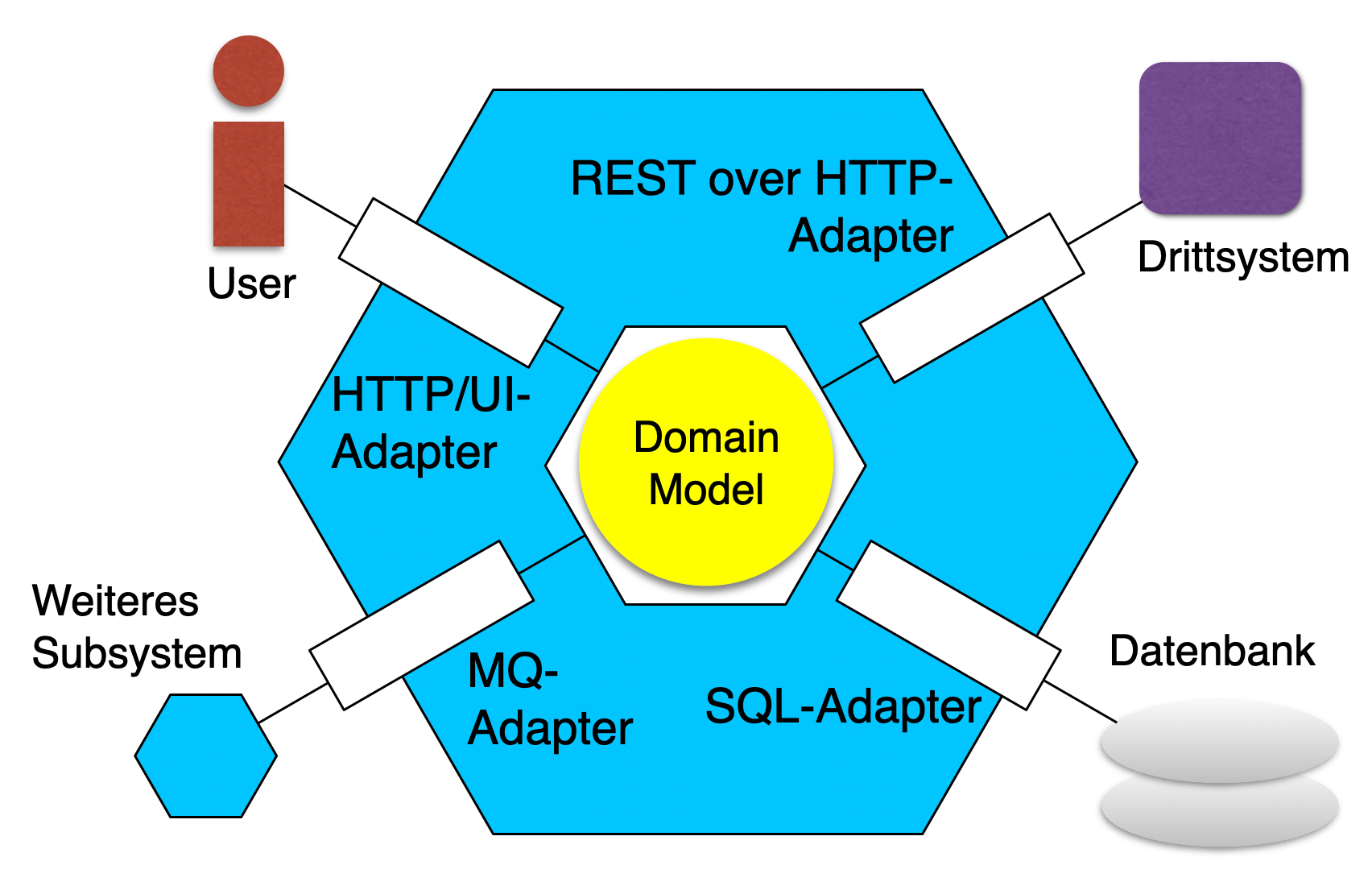
Die hexagonale Architektur, auch als Ports-and-Adapters-Pattern bekannt, basiert auf einer einfachen, aber mächtigen Idee: Die Business-Logik – das, worum es in unserer Anwendung wirklich geht – sollte unabhängig von technischen Details sein. Ob wir PostgreSQL oder MongoDB verwenden, ob unsere API REST oder GraphQL spricht, ob wir auf AWS oder Azure deployen – all das sollte austauschbar sein, ohne dass wir die Kernlogik anfassen müssen.
Im Zentrum steht der Domänenkern, der die Geschäftsregeln enthält. Dieser Kern definiert Ports – Schnittstellen, die beschreiben, was der Kern von der Außenwelt benötigt und was er nach außen anbietet. Die Adapter implementieren diese Ports und übersetzen zwischen der Domänensprache und den technischen Systemen.
Stellen wir uns eine E-Commerce-Anwendung vor: Der Kern enthält Regeln wie "Eine Bestellung kann nur storniert werden, wenn sie noch nicht versendet wurde". Diese Regel ist unabhängig davon, ob wir die Bestelldaten in einer relationalen Datenbank speichern oder in einem Event Store. Der Port definiert "Ich brauche eine Möglichkeit, Bestellungen zu laden und zu speichern". Der Adapter kümmert sich um die SQL-Queries oder API-Calls.
Die Vorteile zeigen sich sofort in der Testbarkeit: Unsere Geschäftslogik lässt sich mit In-Memory-Implementierungen der Ports testen, ohne externe Abhängigkeiten. Wenn wir die Datenbank wechseln wollen, schreiben wir einfach einen neuen Adapter – der Kern bleibt unberührt. Und wenn ein neues Framework oder eine neue Library auftaucht, können wir migrieren, ohne Angst haben zu müssen, dass dabei die Geschäftslogik beschädigt wird.
Parse, don't validate – Typsicherheit als Designprinzip
Es gibt einen subtilen, aber fundamentalen Unterschied zwischen Validierung und Parsing, den viele Codebases ignorieren – zu ihrem eigenen Schaden. Bei der Validierung prüfen wir Eingaben und werfen im Fehlerfall eine Exception oder geben false zurück. Bei erfolgreicher Validierung haben wir aber immer noch denselben Typ wie vorher, meist einen String oder eine primitive Datenstruktur. Die Information "diese Eingabe ist valide" geht verloren, sobald die Validierungsfunktion beendet ist.
function sendEmail(email: string) {
if (!isValidEmail(email)) {
throw new Error("Invalid email");
}
// email ist immer noch ein string
// Ist er wirklich valide? 🤔
emailService.send(email);
}
// Irgendwo anders im Code:
sendEmail("user@example.com"); // ✓ OK
sendEmail("invalid"); // ✗ wirft einen Runtime Error!Validieren in der Domänen-Logik? Nein!
Parsing hingegen erzeugt einen neuen, aussagekräftigen Typ. Aus einem String wird eine Email-Adresse, aus einem Integer wird ein positiver Integer, aus einem JSON-Objekt wird ein validiertes Domänenobjekt. Dieser neue Typ trägt die Garantie in sich: Wenn eine Funktion eine Email als Parameter erwartet, wissen wir, dass diese Email bereits geparst und damit valide ist. Wir müssen nicht erneut validieren.
Betrachten wir ein konkretes Beispiel: In einem traditionellen Ansatz haben wir vielleicht eine Funktion sendEmail(emailAddress: string). Irgendwo in dieser Funktion – oder schlimmer noch, an mehreren Stellen – müssen wir prüfen, ob der String tatsächlich eine gültige Email-Adresse ist. Jeder Entwickler, der diese Funktion verwendet, muss sich daran erinnern, vorher zu validieren. Vergisst jemand das, haben wir einen Bug.
Mit dem Parse-Ansatz definieren wir einen Typ Email und eine Funktion parseEmail(input: string): Result<Email, Error>. Die Funktion sendEmail akzeptiert dann Email, nicht string. Der Compiler zwingt uns dazu, den String zu parsen, bevor wir ihn übergeben können. Unmögliche Zustände – eine ungültige Email in der Sendefunktion – werden unmöglich zu repräsentieren:
import { Result, Ok, Err } from "ts-results-es";
type Email = string & { _brand: "Email" };
function parseEmail(input: string): Result<Email, Error> {
return isValidEmail(input)
? Ok(input as Email)
: Err(new Error("Invalid email"));
}
function sendEmail(email: Email): Result<void, Error> {
return emailService.send(email); // email ist garantiert valide! ✓
}
// Compiler erzwingt Parsing:
const result = parseEmail("user@example.com").andThen(sendEmail);
if (result.isErr()) {
console.error("Error sending email: ", result.error);
}Parsen außerhalb der Domänen-Logik? Ja!
Dieses Prinzip skaliert wunderbar: Positive Zahlen, nicht-leere Listen, validierte IBANs, autorisierte Benutzer – all das können eigene Typen sein, die ihre Invarianten in ihrer bloßen Existenz garantieren. Der Compiler wird zu unserem Verbündeten, und Runtime-Fehler werden zu Compile-Time-Fehlern.
Modularer Aufbau entlang von Bounded Contexts
Software wächst. Was als überschaubares Projekt beginnt, entwickelt sich zu einem komplexen System mit Dutzenden von Konzepten, Hunderten von Klassen und Tausenden von Abhängigkeiten. Ohne eine klare Struktur wird diese Komplexität schnell unbeherrschbar. Die Lösung liegt in der strategischen Aufteilung entlang von Bounded Contexts.

Ein Bounded Context ist ein klar abgegrenzter Bereich, in dem ein bestimmtes Domänenmodell gilt. Nehmen wir wieder unsere E-Commerce-Anwendung:
- Im "Order Management"-Kontext bedeutet "Customer" jemand, der Bestellungen aufgibt – mit Lieferadresse, Bestellhistorie und Präferenzen.
- Im "Payment"-Kontext ist "Customer" jemand mit Zahlungsinformationen und Kreditwürdigkeit.
- Im "Marketing"-Kontext ist es jemand mit Interessen und Segmentzugehörigkeit.
Statt zu versuchen, ein universelles Customer-Modell zu erschaffen, das alle Anforderungen erfüllt (und damit unweigerlich zu kompliziert wird), haben wir mehrere spezialisierte Modelle, jeweils perfekt angepasst an ihren Kontext. Jeder Bounded Context wird zu einem eigenen Modul mit eigener Verantwortlichkeit, eigenen Modellen und eigener Persistenz.
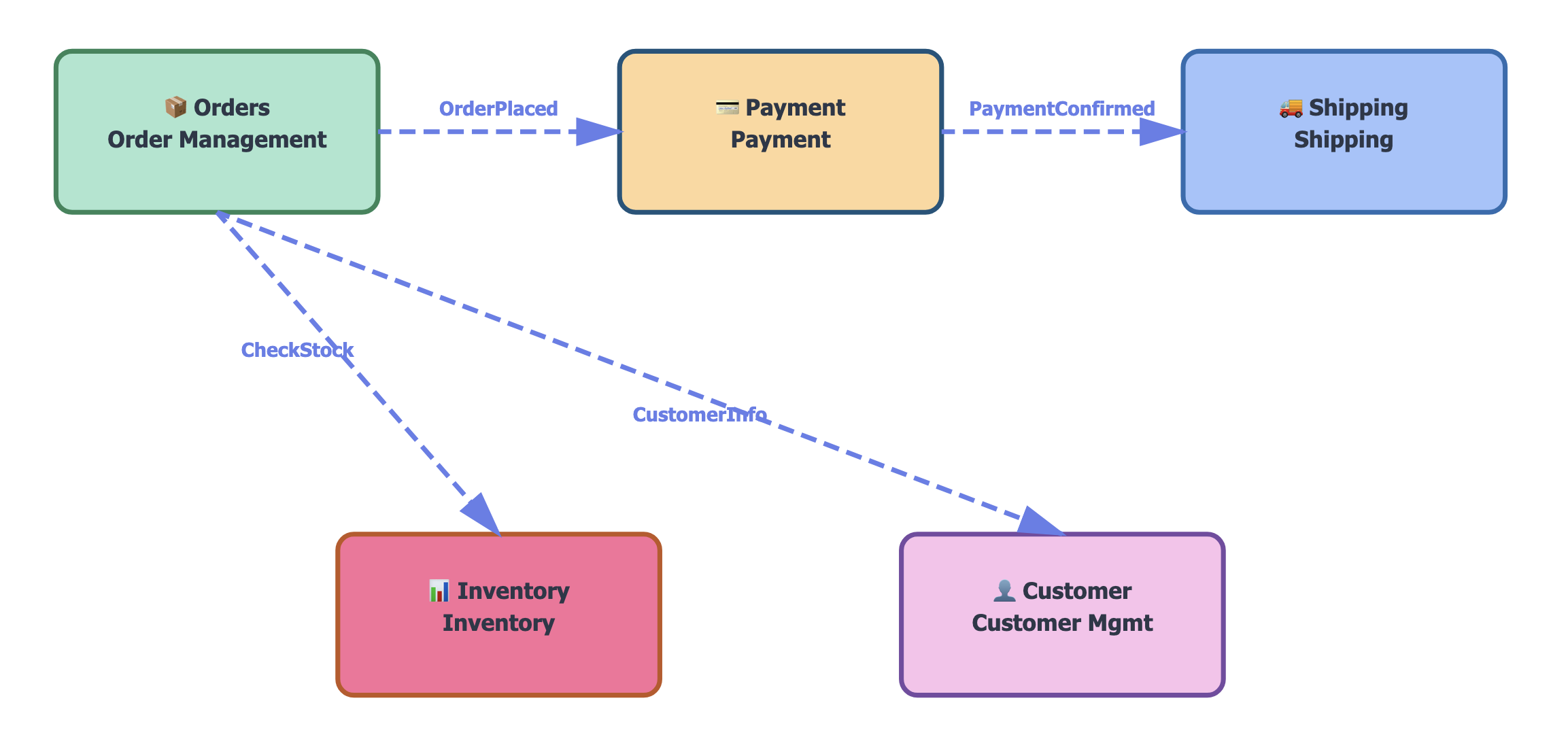
Die Kommunikation zwischen Modulen erfolgt über definierte Schnittstellen. Das Order-Modul publiziert ein Event "OrderPlaced", das Payment-Modul reagiert darauf. Oder das Order-Modul ruft eine API des Inventory-Moduls auf, um die Verfügbarkeit zu prüfen. Wichtig ist: Die internen Details bleiben privat. Das Payment-Modul muss nicht wissen, wie das Order-Modul seine Daten speichert.
Diese Struktur bringt enorme Vorteile: Teams können an verschiedenen Kontexten arbeiten, ohne sich ständig in die Quere zu kommen. Die kognitive Last sinkt, weil man sich immer nur auf einen Kontext konzentrieren muss. Änderungen bleiben lokal begrenzt. Und wenn ein Kontext zu groß wird, können wir ihn in mehrere aufteilen – oder einen Kontext als eigenen Service auslagern, wenn wir das wollen.
Qualitätsattribute – Was macht Code robust und wartbar?
All diese Architekturentscheidungen dienen einem Zweck: Sie schaffen bestimmte Qualitätsattribute, die den Unterschied zwischen Software, mit der man gerne arbeitet, und Software, die man lieber nicht anfassen würde, ausmachen.
Wartbarkeit entsteht durch klare, kohäsive Strukturen und geringe Kopplung. Wenn ich ein Feature ändern muss, sollte ich genau wissen, wo ich anfangen muss, und ich sollte sicher sein können, dass meine Änderung keine unerwarteten Nebenwirkungen in entfernten Teilen des Systems hat. Hexagonale Architektur und Bounded Contexts geben uns genau diese Sicherheit.
Testbarkeit ist kein Zufall, sondern das Ergebnis von Design. Wenn unsere Business-Logik keine direkten Abhängigkeiten zu Datenbanken, HTTP-Clients oder Dateisystemen hat, können wir sie isoliert testen. Ports lassen sich durch Test-Doubles ersetzen, Parsed Types garantieren, dass wir keine invaliden Testdaten erzeugen können. Ein guter Test sollte sich auf das "Was" konzentrieren, nicht auf das "Wie" der Implementierung.
Robustheit bedeutet, dass unsere Software auch unter unerwarteten Bedingungen korrekt reagiert. Das Parse-Prinzip hilft uns dabei enorm: Statt optimistisch anzunehmen, dass Eingaben valide sind, und dann an unerwarteter Stelle zu crashen, scheitern wir früh und explizit. Wir verwenden Result-Typen statt Exceptions für erwartbare Fehler und machen damit Error-Handling zu einem Teil unseres Typsystems.
Verständlichkeit entsteht, wenn der Code die Domäne widerspiegelt. Bounded Contexts verwenden die Sprache des Business. Aussagekräftige Typen – Email, PositiveAmount, AuthorizedUser – dokumentieren sich selbst. Die hexagonale Architektur macht klar, wo Business-Logik lebt und wo technische Details. Code wird zu einer Form der Dokumentation, die nie veraltet, weil sie der ausführbare Code selbst ist (sollten Sie gerade anfangen, sich über diese Aussage aufzuregen, kommentieren Sie bitte unten!).
Performance wird oft als Gegensatz zu guter Architektur gesehen, aber das ist ein Missverständnis. Gute Architektur macht es einfacher, Performance-Probleme zu lokalisieren und zu beheben. Wenn wir unseren Datenzugriff hinter Ports abstrahieren, können wir Caching-Layer transparent einfügen. Wenn unsere Module lose gekoppelt sind, können wir sie unabhängig voneinander skalieren.
Von der Theorie zur Praxis
Die Prinzipien klingen überzeugend auf dem Papier, aber wie setzt man sie um? Der Schlüssel liegt darin, nicht alles auf einmal zu wollen. Selbst in einem Legacy-System können wir schrittweise vorgehen.
packages
├── customer-management
│ └── src
│ ├── adapter
│ │ └── CustomerRepositoryImpl.ts
│ └── domainmodel
│ ├── Customer.ts
│ └── CustomerRepository.ts
├── inventory
│ └── src
│ ├── adapter
│ └── domainmodel
├── order-management
│ └── src
│ ├── adapter
│ └── domainmodel
├── payment
│ └── src
│ ├── adapter
│ └── domainmodel
└── shipping
└── src
├── adapter
└── domainmodelBeginnen wir mit der Struktur: Organisieren Sie Ihren Code zuerst nach Bounded Contexts, erst dann nach technischen Gesichtspunkten:
- Statt einer Struktur wie
controllers/,services/,repositories/haben wirorder-management/,payment/,shipping/. - Innerhalb jedes Kontexts können wir dann nach Hexagonen strukturieren:
domainmodel/für die Kernlogik,adapters/für die Implementierungen. Ports gehören mit nachdomainmodel/, finde ich.
Ein typischer Workflow könnte so aussehen: Ein HTTP-Request trifft auf einen Adapter (z.B. einen REST-Controller). Dieser Adapter parst die Eingabe in Domänentypen – hier kommt "Parse, don't validate" zum Einsatz. Wenn das Parsing fehlschlägt, geben wir sofort einen Fehler zurück. Mit den geparsten Typen rufen wir einen Application Service im Domänenkern auf. Dieser Service verwendet Ports, um mit anderen Teilen des Systems zu interagieren. Die Ports werden durch Adapter implementiert, die mit Datenbanken, externen APIs oder anderen Modulen kommunizieren.
Häufige Herausforderungen: "Aber unsere Datenbank-Entities sind doch schon unser Domänenmodell!" Nein, sind sie nicht. Das Datenbankschema optimiert für Speichereffizienz und Abfragen. Das Domänenmodell optimiert für Verständlichkeit und korrekte Geschäftslogik. Die beiden haben unterschiedliche Zwecke und sollten getrennt sein. Ein Adapter übersetzt zwischen ihnen.
"Das ist doch viel mehr Code!" Kurzfristig ja, ein bisschen. Langfristig nein, weil Sie weniger Zeit mit Debugging, Refactoring und dem Verstehen von Code verbringen. Die kleine Upfront-Investition zahlt sich schnell aus.
"Wie finde ich die richtigen Bounded Contexts?" Hören Sie der Business-Seite zu. Wo verwenden verschiedene Teams unterschiedliche Begriffe für ähnliche Dinge? Wo gibt es fachliche Grenzen? Event Storming ist eine hervorragende Technik, um Kontexte zu identifizieren.
Tools und Techniken
Gute Architektur wird durch die richtigen Tools unterstützt. Statische Typsysteme sind unverzichtbar für "Parse, don't validate" – TypeScript, Rust, Kotlin, F# sind gute Wahl. Dependency Injection Container helfen bei der Verwaltung von Adaptern. Architektur-Tests (z.B. mit ArchUnit) können Regeln wie "Die Domain-Schicht darf keine Adapter importieren" automatisiert überprüfen.
Für Bounded Contexts sind Build-Tools wichtig, die modulare Strukturen unterstützen. Monorepos mit Tools wie Nx, Turborepo oder Gradle können helfen, klare Modulgrenzen zu definieren und durchzusetzen. Dokumentation entsteht am besten direkt aus dem Code – C4-Diagramme, die Kontexte und ihre Beziehungen zeigen, ADRs für Architekturentscheidungen.
Und vergessen Sie nicht Code Reviews: Architektur ist ein Team-Sport. Regelmäßige Diskussionen über Struktur, Verantwortlichkeiten und Qualität halten alle auf derselben Linie.
Der Return on Investment
Lassen Sie uns ehrlich sein: Gute Architektur kostet Zeit. Aber schlechte Architektur kostet mehr – sie kostet Zeit bei jedem einzelnen Feature, das danach kommt. Die Frage ist nicht, ob wir uns gute Architektur leisten können, sondern ob wir uns schlechte Architektur leisten können.
Teams, die diese Prinzipien umsetzen, berichten von bemerkenswertem Wandel: Features, die früher Wochen dauerten, sind in Tagen fertig. Bugs treten seltener auf und sind schneller zu fixen. Neue Teammitglieder finden sich schneller zurecht. Der Code macht wieder Spaß.
Die hexagonale Architektur gibt uns die Freiheit, technische Entscheidungen zu revidieren, ohne die Geschäftslogik anzufassen. "Parse, don't validate" verwandelt Runtime-Bugs in Compile-Time-Fehler. Bounded Contexts lassen Teams parallel und unabhängig arbeiten.
Skills aufbauen
Sie müssen nicht Ihr gesamtes System morgen umkrempeln. Beginnen Sie mit einem neuen Feature oder einem Modul, das ohnehin überarbeitet werden muss. Wenden Sie diese Prinzipien konsequent an. Sammeln Sie Erfahrung. Lernen Sie, was in Ihrem Kontext funktioniert.
Etablieren Sie Team-Standards: Wie strukturieren wir Module? Wann erstellen wir neue Typen? Wie testen wir Services? Diese Standards wachsen mit der Zeit und werden zum gemeinsamen Vokabular Ihres Teams.
Und investieren Sie in Lernen: Gute Architektur ist ein Handwerk, das man durch Übung perfektioniert. Diskutieren Sie Design-Entscheidungen im Team. Schauen Sie sich Open-Source-Projekte an, die diese Prinzipien umsetzen. Experimentieren Sie in Spike-Projekten.
Die Software, die wir heute schreiben, wird uns morgen danken – oder verfluchen. Die Entscheidung liegt bei uns.
Wie es weitergeht
Wir haben heute gesehen, dass wir der KI zeigen müssen, welche Kriterien wirklich gute Architektur ausmachen. Das nächste Mal geht es um saubere Fehlerbehandlung und souveränes Management von Asynchronität: Was man der KI alles zeigen muss, damit sie Code macht, der tatsächlich in Produktion funktioniert.
Bitte kommentieren Sie weiter unten: Was möchten Sie in dieser Serie noch gern behandelt haben? Welche Fragen haben Sie? Was haben Sie selbst schon probiert? Was davon hat gut geklappt, und was waren Ihre schlimmen Erlebnisse mit KI-Assistenten?
Ich freue mich auf das, was Sie zu sagen haben. Wenn Sie neue Folgen der Serie automatisch per Email haben wollen, abonnieren Sie sie doch gleich hier!
Alte Folge verpasst? Hier geht es zur ersten Folge mit Inhaltsverzeichnis.
Kommentare